
 加入会员
加入会员





🪐前言
我有一个朋友(不是编的,是真有),做了一个 B2C 独立站。他看了一篇公众号文章说"红色按钮转化率更高",就把所有 CTA 按钮从蓝色改成了红色。一周后,订单从 68 单涨到了 74 单。他兴奋地发朋友圈:"红按钮大法好!"
我问他:"同一周你有没做其他动作?"
他想了想:"嗯……周三是 Black Friday 促销季第一天。"
这就是整个 A/B 测试领域最普遍的问题——把相关性当成了因果性,把噪点看成了信号。与其说 A/B 测试是技术活,不如说它是逻辑活。这篇文章不写公式推导,只把运营人真正需要的统计概念、排期原则、常见误区和结果解读方法讲清楚。
一、先理解两个最容易被误用的统计概念
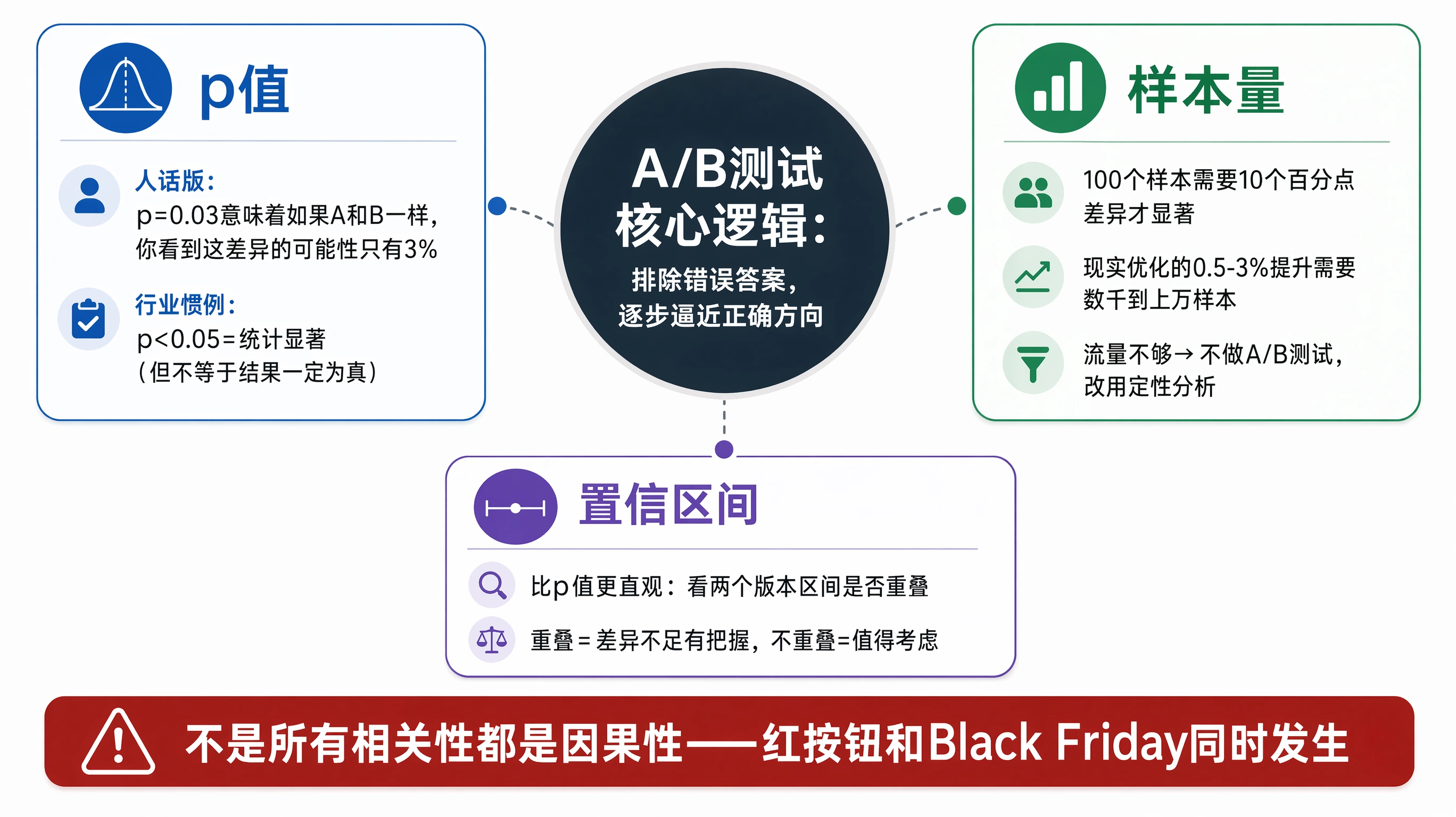
你不需要知道 p 值的数学推导——你需要的是能读懂它、不被人忽悠,以及不自己骗自己。
🎲 p 值到底是什么(人话版)
假设你做了一个实验:A 版本和 B 版本各跑了 1000 个用户,B 版本转化率高 0.3%。你知道你不知道这 0.3% 是不是真的"B 更好",于是一个叫 p 值的数字跳出来告诉你:
p = 0.03 的意思是"如果实际上 A 和 B 一模一样(没有效果差异),你看到 0.3% 这种结果的可能性只有 3%。"
翻译成一句话:p 值越小,"这拨效果其实是偶然"的可能性越低。
行业惯例里,p < 0.05 被叫做"统计显著"。但这不意味着"结果一定是真的"——它只是一个门槛。p = 0.04 和 p = 0.06 其实差不了多少,但在很多决策里,前者被当成铁证,后者被当成不成立,这本身就是误解。
🔢 样本量不足:最隐蔽的"假显著"陷阱
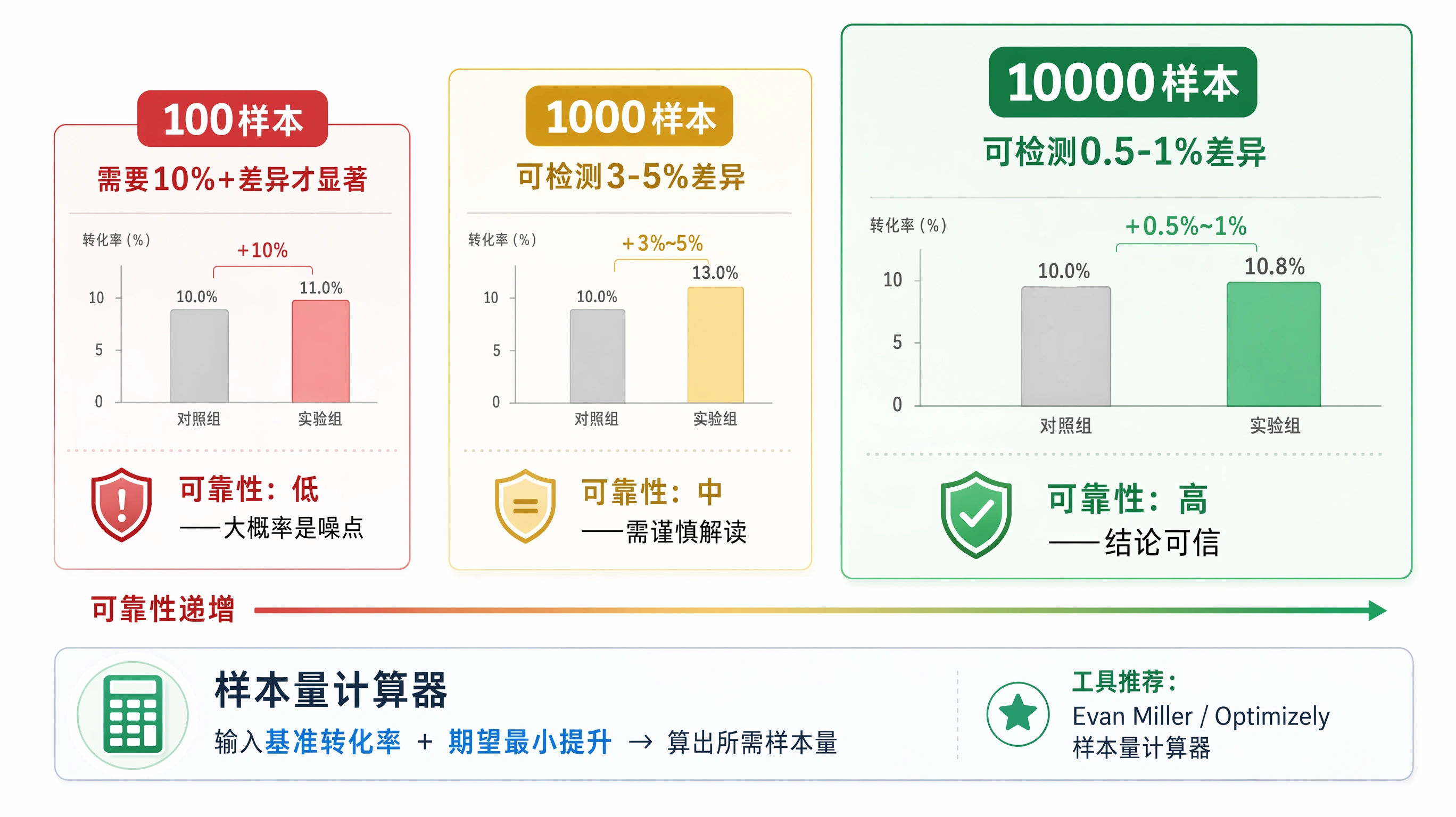
这是最容易踩的坑。100 个用户跑出的"显著结果"和 10000 个用户跑出的"显著结果",可信度天差地别。
一个直观的例子,摘自 Dan Siroker 等人广为引用的运营实验记录:如果你只有 100 个样本,A 和 B 的转化率差异得大到 10 个百分点以上,才能在统计上显著。而现实中大多数优化动作的提升幅度在 0.5%-3% 之间,这个范围需要的样本量是数千到上万级别的。
怎么做:
- 在开测之前,先用样本量计算器估一下需要多少人:用 Evan Miller 的在线计算器 或者 Optimizely 的样本量工具,输入你当前的基准转化率和期望的最小提升幅度,它会告诉你最少需要多少流量
- 如果流量不够——比如你的站每天只有 100 个独立访客,一个测试需要 20000 个样本——那你的结论就是不可靠的。这种情况下,宁可不做 A/B 测试,改用定性分析(热图、录屏回放)做优化判断
⚖️ 置信区间:比 p 值更直观的决策工具
p 值的局限在于它是一个"是或否"的二元判断。相比之下,置信区间更友好:
如果 B 版本转化率是 3.2%,95% 置信区间是 [2.9%, 3.5%],那意味着:我们有 95% 的把握认为,B 的真实转化率在 2.9% 到 3.5% 之间。
看两个版本的置信区间是否重叠,比你盯着 p 值更直观。重叠意味着差异不足够有把握,不重叠才值得认真考虑。
二、测试排期的三条铁律
我见过最离谱的一次测试排期:周四上线,下周二看数据,宣布胜者。正好跨越一个周末——而周末的用户行为和平日完全不同。
📅 铁律一:至少跑满两个完整周期
一个"周期"是什么?对你来说,可能是:
- 一周:如果你的业务有明显的周末/工作日差异(很多 B2C 周末流量更高)
- 一个采购决策周期:如果是 B2B,客户的采购决策可能从看到邮件到周一晨会讨论——周期是 5 天到 2 周不等
- 一个月:对于低流量 B2B 询盘站(日均 < 500 UV),一个有效测试可能需要 4-6 周
最低要求:无论你的业务规模,A/B 测试至少要跑满两个完整的星期。只包含一个周末,你不知道周中的趋势能持续。不包含周末,你不知道工作日的模式是否全面。
📅 铁律二:不要在促销季、节假日、新品发布期间做测试
促销季的用户行为和平时完全不同——促销期间转化率可能翻倍甚至翻几倍,但这种数据不能代表"你的优化有效"。
如果 Black Friday 这一周你的转化率从 2% 涨到 4%,是按钮颜色变了的效果还是折扣力度?没人能分得清。一律在"正常时段"做测试,把促销期排除在外。
📅 铁律三:不要在测试期间改动其他东西
这听起来像废话,但现实中很多人同时改了两三样东西然后试图把效果归因给其中一个。如果你改了产品页主图,同时也调了价格——即使 A/B 测试的分流是随机的,你也无法判断是图在起作用还是价格在起作用。
一次只测一个变量。可以接受测试周期拉长,但不要同时多变量叠加。
三、你最容易犯的 4 个 A/B 测试误区
🐛 误区一:看到"显著"就立刻停止测试(Peeking Problem)
这是统计世界里最经典的陷阱之一。如果你每天都在看测试面板,看到"p<0.05"就立刻喊停——那么你的假阳性概率不是你以为的 5%,而是可能高达 20%-30%。
为什么?因为 p 值本身会波动。一场测试的前几天,样本量不足,p 值可能因为随机因素偶尔"越过 0.05 红线"。如果你在这个时候停止,你大概率是在追一个假信号。
正确做法:在测试开始前就定好"最少天数"(比如 14 天)和"最少样本量"(计算器出来后写死),两个条件都满足之后再看 p 值和置信区间。中间的数据波动全部忽略。
🐛 误区二:只测大改动,不测小迭代
很多人觉得"测就要测一个大的"——比如首页全部重做。但这种测试的问题是:即使胜了,你也无法拆解出"到底是哪个改动的效果好"。A/B 测试最有价值的是单一变量的迭代积累。
一个更好的策略是:找到一个有明显提升的动作之后,在新的基线基础上,继续测试下一个变量。这叫"攀登式测试"(Cumulative Testing),最终的效果是叠加的。
🐛 误区三:只看转化率,不看其他指标
CTA 按钮变了颜色,注册量涨了 15%,好消息。但有没有看后续的活跃率?有没有看 30 天退货率?也许按钮的视觉更激进,吸引了更多"顺便注册看看"的用户,但他们的长期价值不如原来。
每次测试至少看三个维度的指标:
- 主指标(你要优化的那个,比如点击率)
- 下游指标(点击之后发生什么,比如注册完成率、购买率)
- 负面指标(这个改动有没有副作用,比如退货率、客服投诉量)
🐛 误区四:用 A/B 测试代替用户研究
A/B 测试能告诉你"哪个更好",但告诉不了你"为什么更好"。如果你测出了一个大的提升,一定要回头用定性方法——录屏回放、用户访谈、热图——去理解背后的原因。理解原因才能复制成功到其他页面,而不是每次都要"盲猜+测试"。
四、一个完整的测试实战案例:B2B 询盘表单 CTA 文案测试
讲一个我自己做过的案例,让你看看完整的测试闭环是什么样。
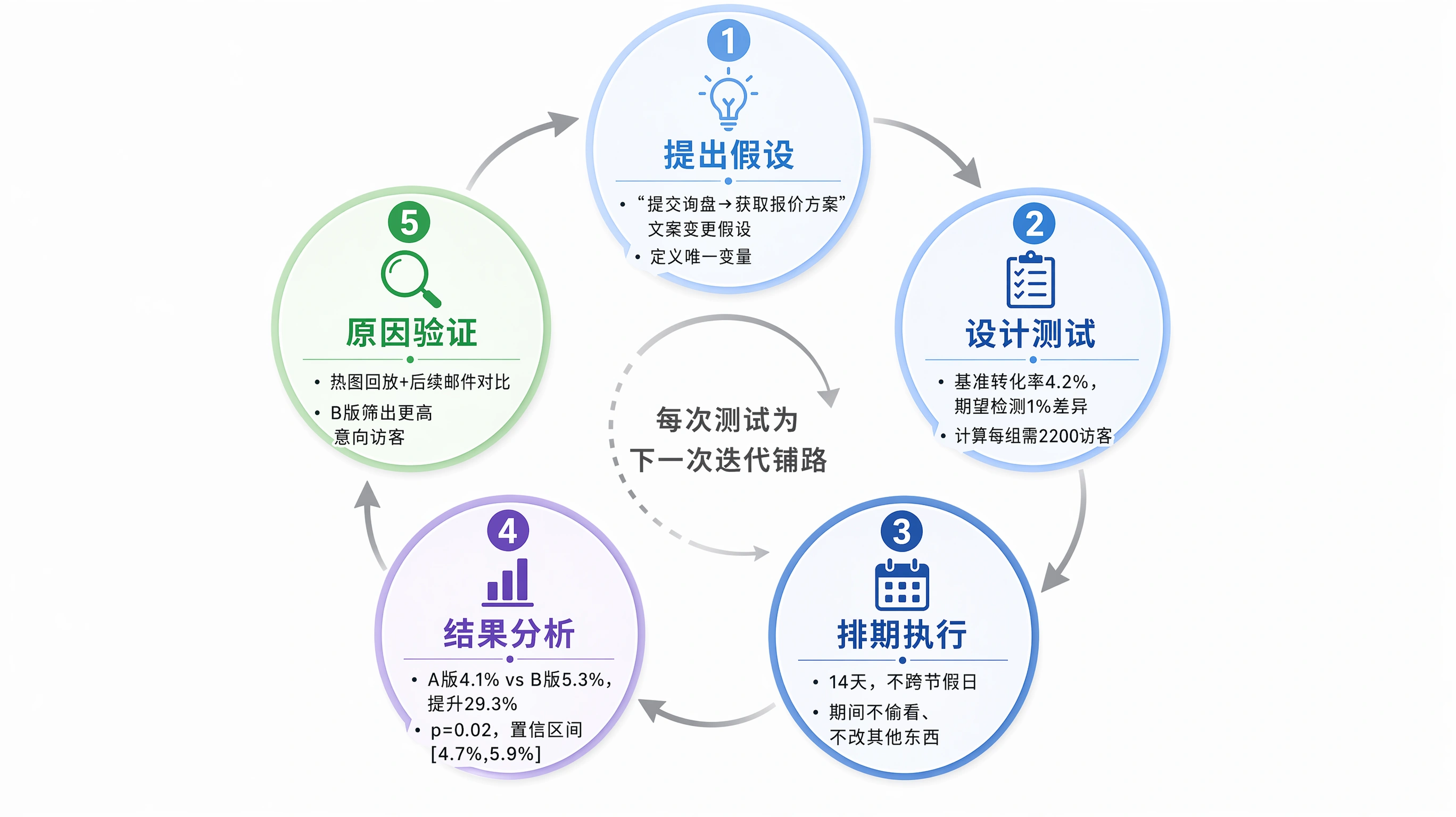
📝 背景
一个做模具出口的 B2B 站,他们的询盘表单 CTA 按钮文案是"提交询盘",点击率 4.2%(相对于访问表单页面的访客数)。
🎯 假设
"提交询盘"这个文案对客户来说,暗示了一个承诺和义务(我需要提交我的信息给你)。改成更强调"获取"而非"给予"的文案,可能提升点击率。
🧪 测试设计
- A 版本(对照组):按钮文案"提交询盘",蓝色
- B 版本(实验组):按钮文案"获取报价方案",同一个位置的同一个按钮,蓝色不变
- 唯一变量:文案,其他一切完全相同
- 样本量计算:基准点击率 4.2%,期望检测最小提升 1 个百分点(到 5.2%),计算结果需要每组约 2200 个访客
- 排期:14 天,不跨节假日
📊 结果
14 天后,累计每组各约 2400 个访客:
- A 版本点击率:4.1%
- B 版本点击率:5.3%
- 提升幅度:29.3%(相对提升)
- p 值:0.02(<0.05,显著)
- 95% 置信区间:B 版本 [4.7%, 5.9%],与 A 版本 [3.6%, 4.6%] 仅有微小重叠
结论:文案变更有显著效果。
🔍 回头验证原因
热图回放显示,B 版本按钮的 hover 率和点击密度确实更高。但更关键的洞察来自后续邮件对比:A 版本进来的人平均回复"我已经了解了你们的产品"占比 38%,B 版本的人说"请给我报价"占比 52%。"获取报价方案"这个词汇实际上在第一次接触就筛出了更有明确采购意向的访客。
这个小案例说明:A/B 测试的价值不在于最后的数字,而在于通过数字理解了用户行为模式的变化。
五、WordPress 上的 A/B 测试工具怎么选
| 工具 | 适合场景 | 核心特点 | 费用 |
|---|---|---|---|
| Google Optimize(已停用) | — | Google已关闭,建议迁移到其他方案 | 已不可用 |
| Nelio A/B Testing(WP插件) | WP深度集成 | 直接对页面、帖子、标题做A/B,结果在WP后台看 | 免费版限制500次浏览/月;付费 €24/月起 |
| VWO (Visual Website Optimizer) | 中大型站 | 可视化编辑器+热图+目标追踪,完整实验平台 | 免费试用30天;付费版本需询价 |
| AB Tasty | 企业级 | 实验管理 + 个性化 + AI辅助分析 | 需询价 |
我的建议:
- 小站先上 Nelio A/B Testing 免费版练手,跑小规模测试理解流程
- 月流量 > 10,000 UV 后考虑 VWO,它的可视化编辑器对非技术运营最友好
- 如果你用的是 GA4 + Google Tag Manager,可以用 GTM 的自定义事件分流来免费搭一个基础 A/B 框架——但需要一定的技术配置
⚠️ 关于 Google Optimize:Google 已于 2023 年 9 月 30 日关闭此项服务。市面上很多文章还在推荐它,注意辨别时效性。

总结:A/B 测试运营人的自检框架
做每一次 A/B 测试之前,把下面这六个问题过一遍:
- 我测的是什么 —— 是不是只改了一个变量?
- 需要多少样本 —— 用过样本量计算器了吗?最少样本数定好了吗?
- 排期合理吗 —— 至少两个完整周期,避开了节假日和促销季?
- 什么时候看结果 —— 是预先设定好的时间点,不是"每天偷看"?
- 看哪些指标 —— 主指标、下游指标、负面指标三个维度都覆盖了吗?
- 如果不显著怎么办 —— 不显著也是一种结果,记录下来,帮团队积累认知
A/B 测试不是给你正确答案的魔法盒子,它是一条帮你排除错误答案、逐步逼近正确方向的路径。用好了,每一次测试都在给下一次迭代铺路。
下一篇推荐阅读:复购率提升与客户生命周期管理:RFM模型怎么用、LTV怎么算。A/B 测试帮你在前端不断优化转化,复购率则决定了你整个商业模型的上限。
📥 可下载资源:本文配套的《A/B测试排期规划表》和《测试结果记录模板》可在公众号后台回复「AB模板」获取。


之前搞过测试,同事天天偷看数据,看到p<0.05就喊停,结果上线后效果打折,原来peeking problem是真的。
那个“提交询盘”改成“获取报价方案”的案例挺实在的,回头我也试试看。
如果日均UV不到500,一个测试要跑一个月,老板能等得了吗?
说了半天,不还是得先有流量,小破站测个鬼。
感觉按钮颜色那个例子太真实了,我们之前也干过,还以为是红色起效,结果是赶上大促。